trebek
2 min read
7 views
What you're missing
Jeopardy! is a ritual for you, and you want to keep up with it or train for one day walking
onto the set of Alex Trebek studios. You learn best through repetition and quizzes, and need
structured notes to study from - but there's no easy way to get it from the vast library
of Jeopardy! video content.
Why you need this
You want to own your personal Jeopardy! knowledge base, to be able to quiz yourself on
categories you want to study, and be able to look up any answer and its context in seconds.
There's a few options for this, but none of them are great.
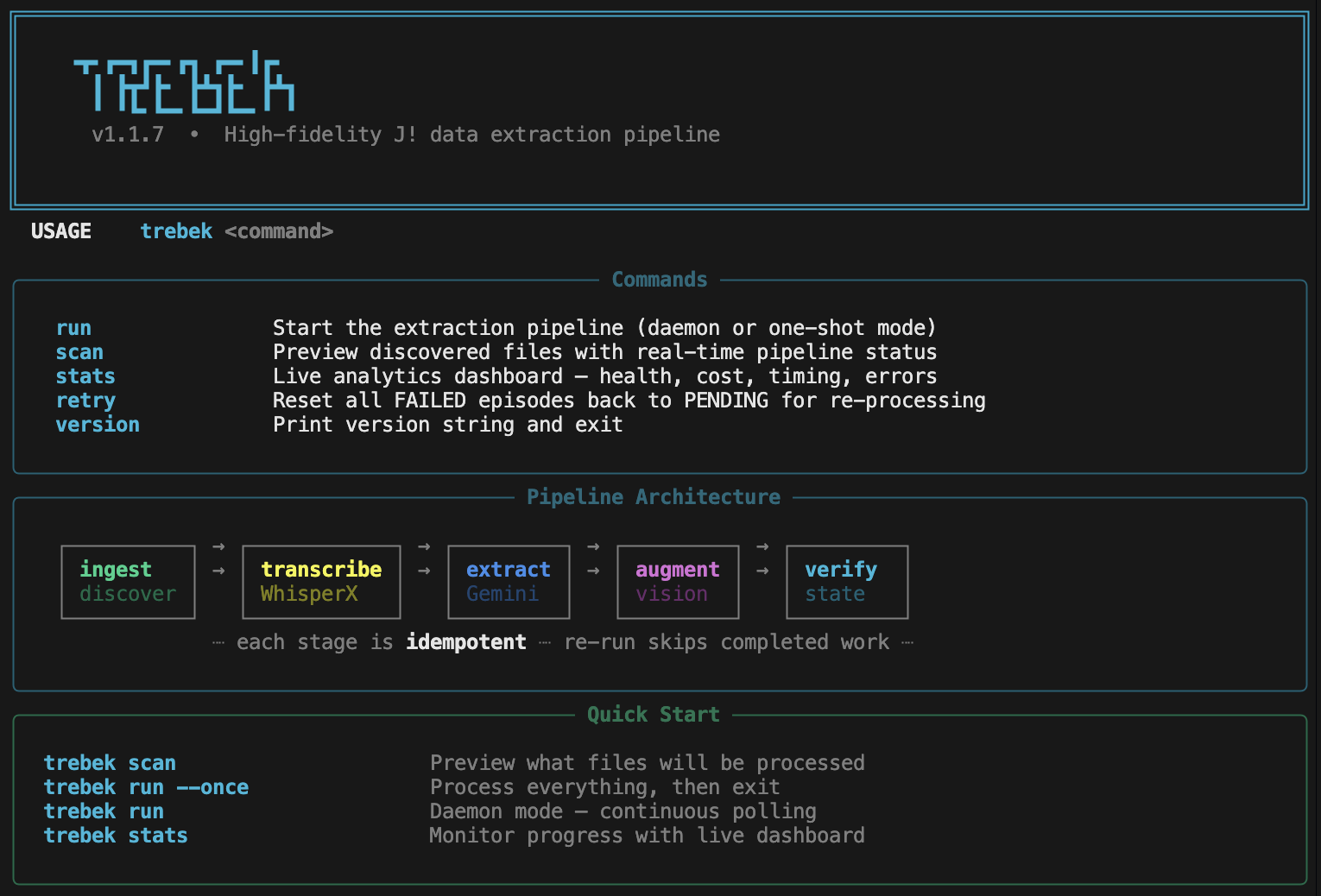
Trebek is a crash-immune pipeline for extracting structured data from Jeopardy! episodes.
It handles the messy parts like inaccurate transcriptions, episodes splitting across two
files, and more, so you can focus on studying.
How do I get this?
Prerequisites: Python 3.11+ and a free Gemini API key. An NVIDIA GPU is recommended for WhisperX transcription. Docker is the easiest path since it bundles all GPU dependencies for you.
Hybrid mode (recommended)
The lightweight CLI runs natively while GPU workloads are delegated to the official Docker image:
1pip install trebek2echo "GEMINI_API_KEY=<your_key_here>" > .env3trebek run \4 --input-dir </path/to/your/videos> \5 --docker
Full Docker deployment
1git clone https://github.com/arvarik/trebek.git && cd trebek2cp .env.example .env3# Set GEMINI_API_KEY4docker compose up -d
The pipeline is fully crash-immune. Kill it at any point and it resumes exactly where it left off via SQLite-backed state tracking. Run trebek stats for a live dashboard of pipeline health, cost tracking, and stage timing.